一次服务拉出的问题排查
问题描述
服务实例健康检测拉出
可能原因
- 应用在请求响应变慢、频繁FullGC
- 机器部署的虚拟机或Docker容器重启
- 机器上部署应用性能出现问题
- 网络问题
排查思路
业务监控排查
- 业务流量
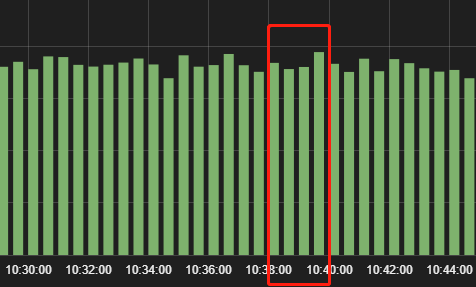
查看业务ES看板,发现流量在此刻比较稳定,排除流量剧增导致的原因
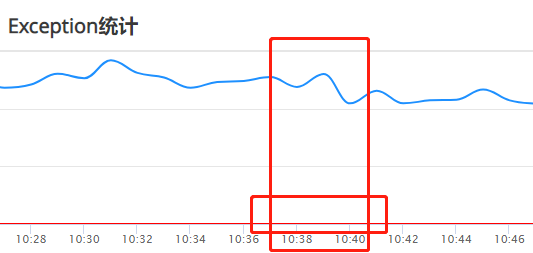
- 异常量
查看异常CAT看板,发现此刻并未有大量异常抛出,排除大量异常造成负载剧增导致的原因
性能监控排查
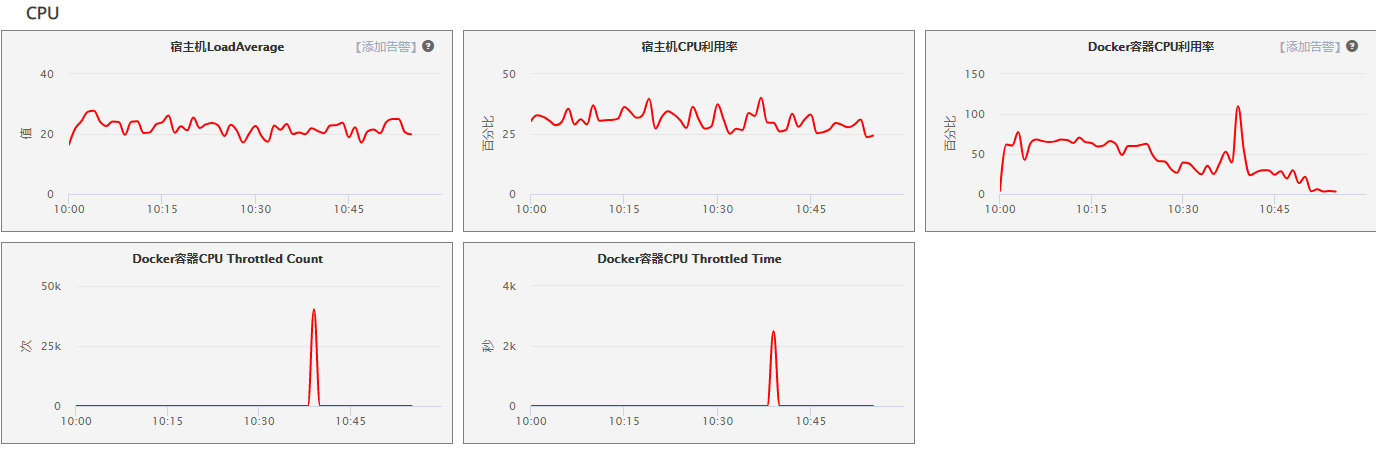
- 宿主机 CPU
宿主机CPU在拉出时间节点并未有明显波动 : 排除CPU泄露导致的原因
- docker CPU
见dockerCPU以及(throttled count/throttled
time)大量升高,怀疑是docker容器重启导致,进一步排查
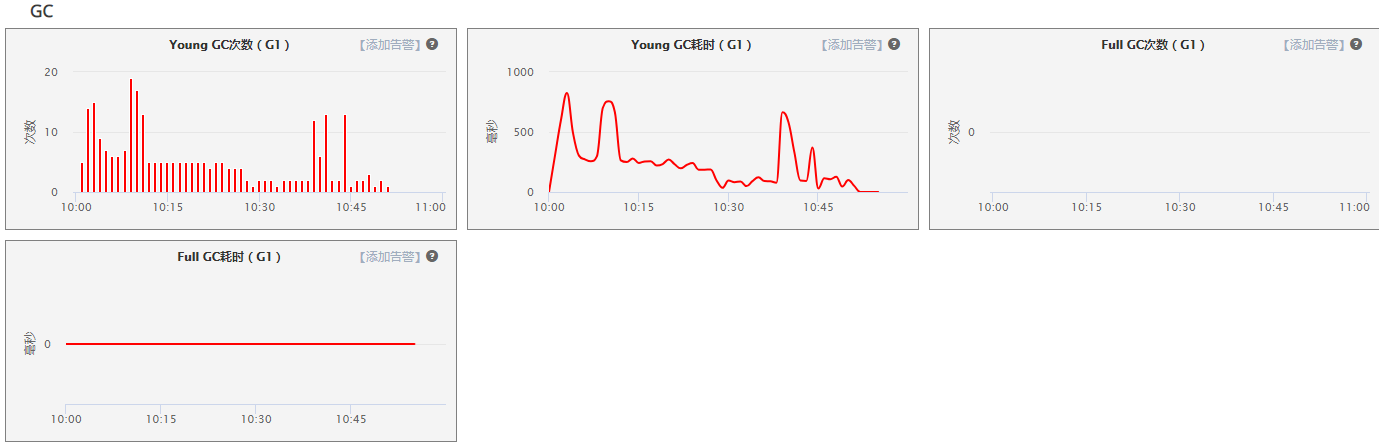
- JAVA GC
youngGC次数 / youngGC耗时 在拉出节点有明显升高,添加为怀疑点
注:youngGC耗时不应超过1sFullGC次数 / FullGC耗时 未见明显,排除FullGC导致原因
注:FullGC耗时不应超过5s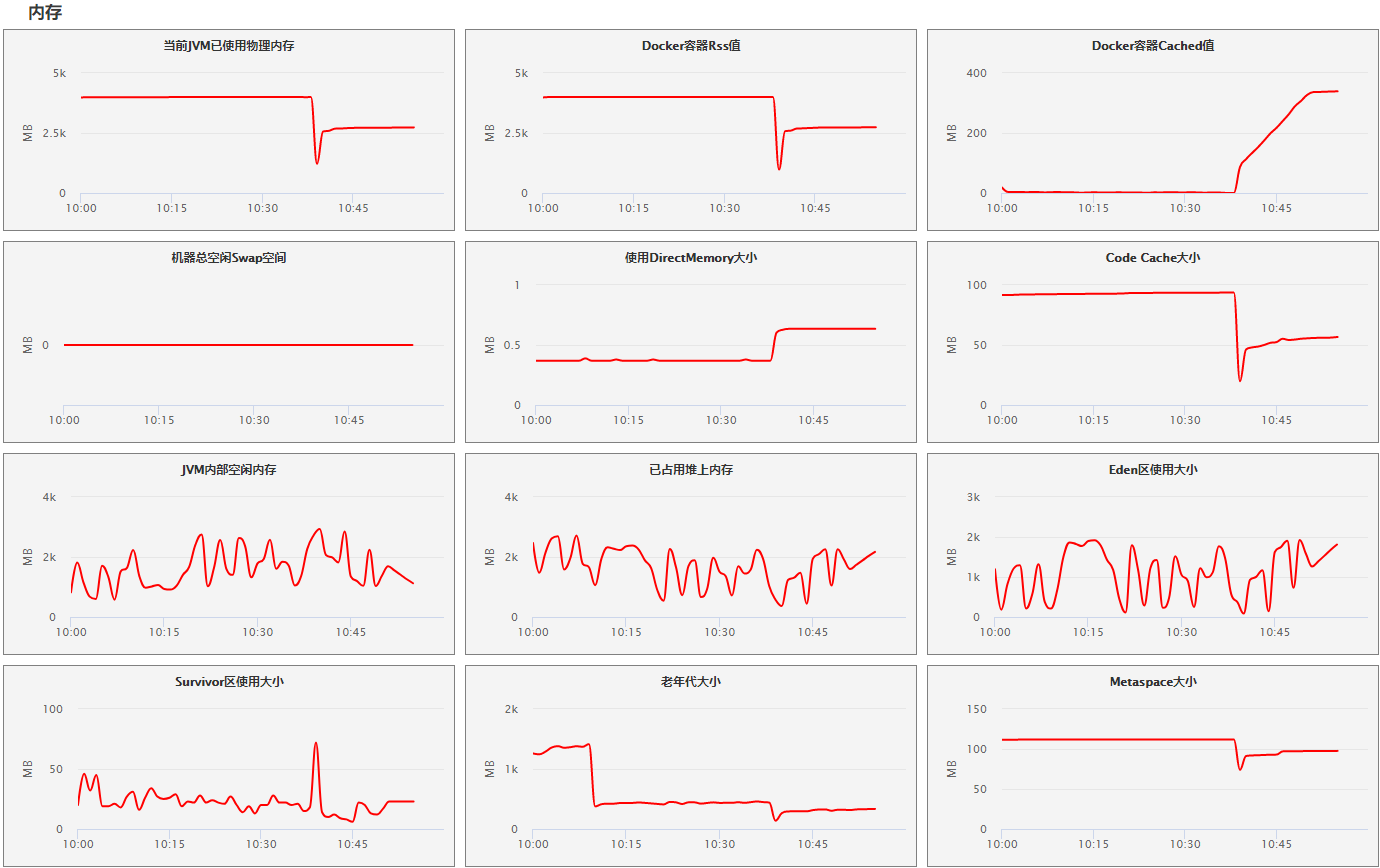
- 宿主机 内存
swap交换空间无变化,没有内存页换入换出,排除程序因为硬盘读取导致的性能下降原因
directMemory直接内存使用上升,怀疑是JVM启动时,大量加载类文件和元数据导致,由此推断可能有重启
- docker 内存
docker rss值接近JVM物理内存,说明没有额外的文件缓存,可以直接对照JVM物理内存进行排查
docker容器cached值大幅上升,应该是docker容器重启时docker
build缓存创建镜像导致。由此推断,可能是docker容器发生了重启
- JVM 内存
JVM空闲内存无明显变化
JVM堆上内存无明显变化
JVM EDEN无明显变化
JVM Survivor
JVM老年代
JVM metaspace
CSS
由以上推断并非由JVM主动发起的重启
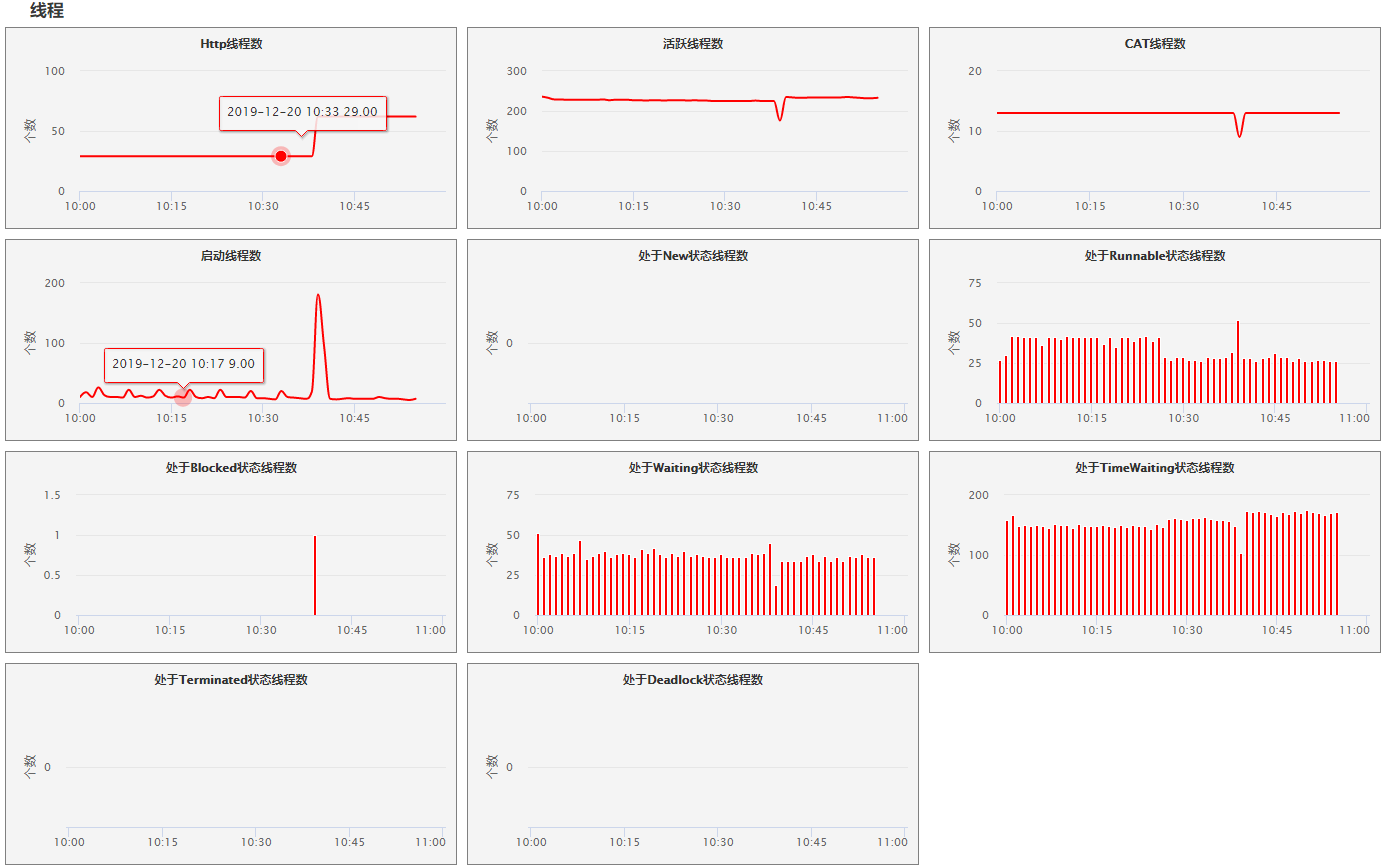
- JVM 线程
磁盘
文件句柄

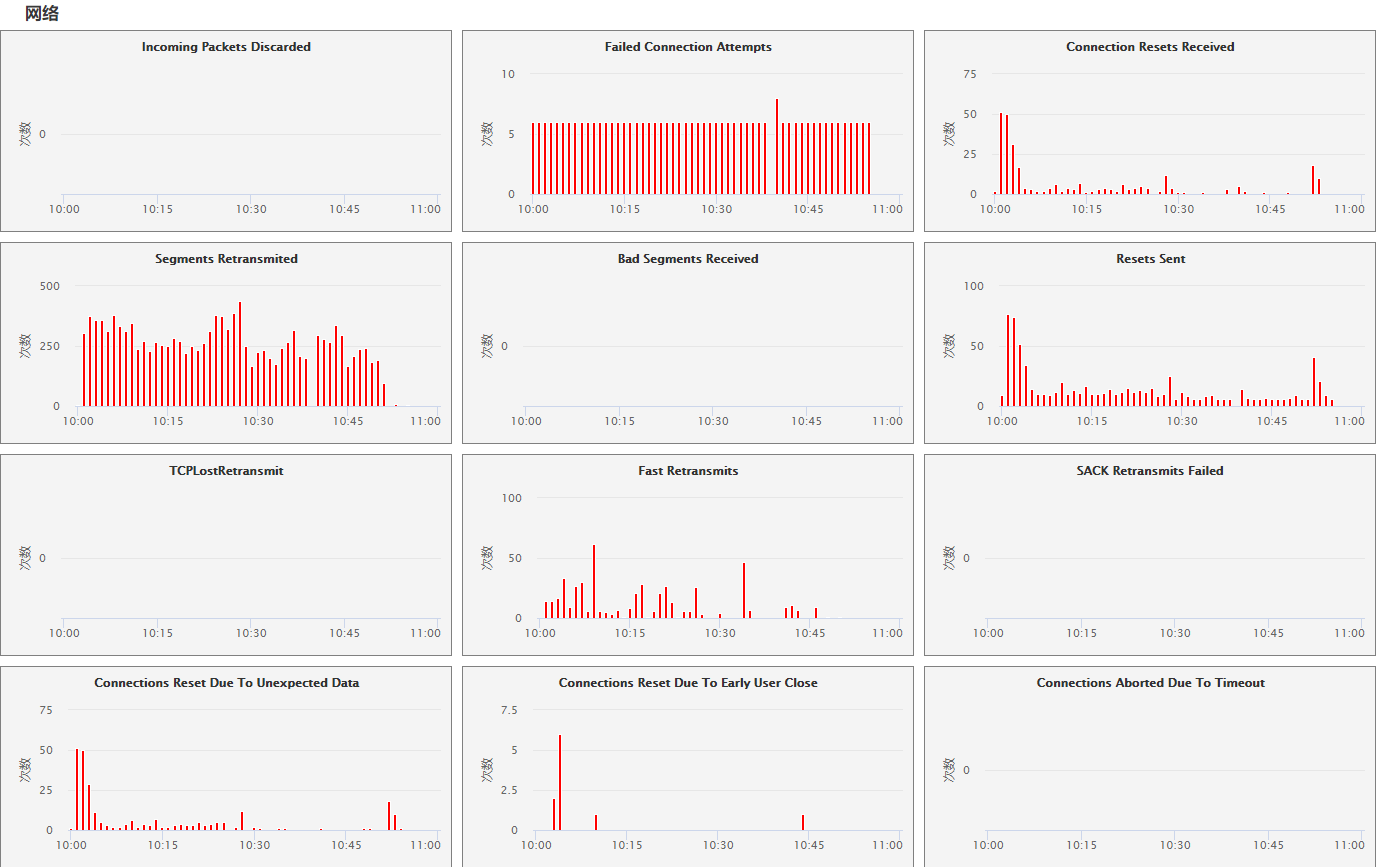
- 网络
查看”Failed Connection
Attempts”连接尝试失败数量,见有轻微上升,可能由服务重启导致,怀疑点不大
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 wshten@gmail.com
文章标题:一次服务拉出的问题排查
本文作者:KevinTen
发布时间:2019-12-20, 00:00:00
最后更新:2019-12-20, 20:34:06
原始链接:http://github.com/kevinten10/2019/12/20/问题排查/问题排查-服务拉出/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

