ServiceMesh--Ready for Cloud Native
Ready for Cloud Native?
我对Service Mesh的第一个担忧,来自 Cloud Native。
作为Cloud Native的忠实拥护者,我不怀疑Cloud Native的价值和前景。但是,我担心的是:准备上service mesh的各位,是否都已经做到了ready for Cloud Native?
如何从非Service Mesh体系过渡到Service Mesh?
即使一切都ready,对于一个有存量应用的系统而言,绝无可能在一夜之间就将所有应用都改为Service Mesh,然后一起上线。
必然会有一个中间过渡状态,一部分应用开始搬迁到Service Mesh,大部分还停留在原有体系。那么,如何在过渡阶段让Service Mesh内的服务和Service Mesh外的服务相互通讯?
发展路径
这里有三条发展路径可选:
先Cloud Native,再Service Mesh
理论上说,这是最合理的:先把底层基础设施铺好,再在其上构建上层业务应用。
具体说,就是先上云/容器/k8s,应用暂时维持原状。不管是单体应用,还是基于Dubbo/Spring Cloud等侵入式开发框架的微服务应用,先上云再说。更直白一点,上k8s。
等待Istio/Conduit成熟之后,再迁移到Service Mesh方案。
先Service Mesh,再Cloud Native
这个方案理论上也是可行的:先用Service Mesh方案完成微服务体系建设,之后再迁移到k8s平台。
之所以说理论上没有问题,是指Service Mesh从设计理念上,对底层是不是容器并没有特别要求。无论是容器/虚拟机/物理机,Service Mesh都是可行的。
同时上Service Mesh加Cloud Native
通常来说我们不赞成同时进行这两个技术变革,因为涉及到的内容实在太多,集中在一起,指望一口气吃成大胖子,容易被噎住。
但是不管怎么样这条路终究还是存在的,而且如果决心够大+愿意投入+高人护航,也不失是一个一次性彻底解决问题的方案,先列在这里。
问题所在
如何从非Service Mesh体系过渡到Service Mesh?
我们需要考虑的是:
即使一切准备就绪,对于一个有存量应用的系统而言,绝无可能将所有应用都一起改为Service Mesh,然后一夜之间上线。
必然会有一个中间过渡状态,一部分应用开始搬迁到Service Mesh,一部分还停留在原有体系。
那么,在过渡阶段,Service Mesh内的服务和Service Mesh外的服务在通讯时会遇到哪些问题?
场景分析
我们来看一个具体的例子,有三个服务,调用关系分别是A->B->C,然后在最前面架设API Gateway。非常典型的微服务体系:
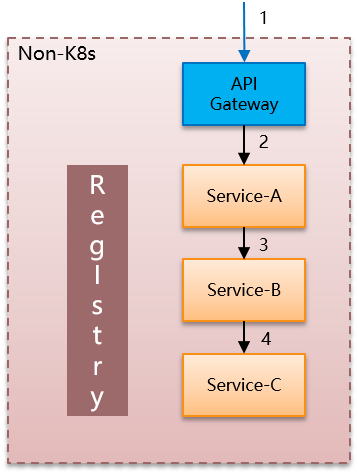
这里可以是spring cloud/dubbo/motan等各种侵入式微服务架构,左边的注册中心/registry的实现也可以有多种,服务间通讯的方式也不尽相同。但是,都不影响我们的讨论。
上图可以看到,在标准的微服务框架中,处理这样一个请求,调用方式是清晰明了的。
如果开始转向Service Mesh体系,无论是Istio/Conduit,都会引入一个新的k8s体系。为了充分演示,我们选择将服务B转移到Service Mesh。调用关系就一下变成复杂:
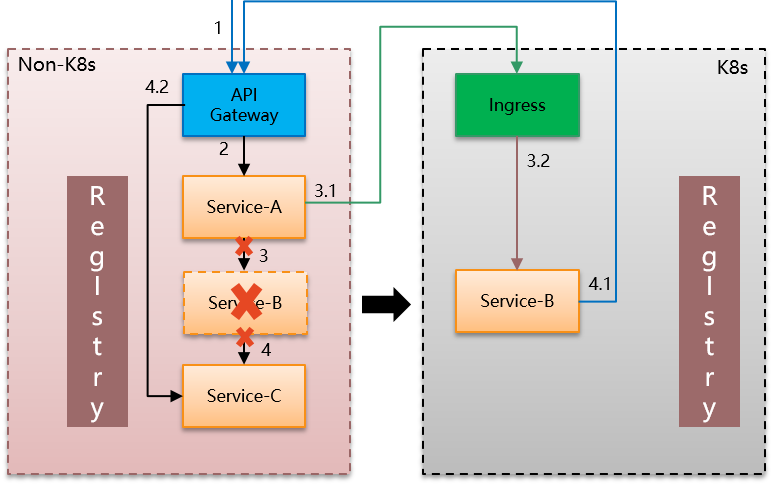
这里我们引入两个术语(TBD:应该是业界通用术语吧?待确认):
- 东西向通讯:指微服务间相互调用
- 南北向通讯:指外界访问微服务体系,通常是通过API Gateway
当B被迁移后,B原有的上游调用(A调用B)和下游调用(B调用C),虽然业务语意上依然还是东西向通讯,但是由于跨了体系导致原有的调用方式被打破。只能另想办法,目前看通常的做法都是改走南北向通讯。
影响
而这个改变会带来巨大的工作量:
B的所有上游服务都要修改
原有的标准服务间通讯(通过sdk进行服务发现/负载均衡等)都废弃,需要改为对k8s体系入口如Ingress的调用。然后在Ingress这边也要做好对服务B的配置。
B对所有下游服务的调用方式都要修改
同样,原有的标准服务间通讯都废弃,需要改为对API Gateway的调用。然后在API Gateway这边也要做好对下游服务的配置。
而通讯机制改变带来的工作量不是唯一的问题,还有一个内部服务对外暴露的问题:
在原有体系中,服务B和服务C都是内部服务,完全可以不对外暴露,API Gateway访问的只是服务A
迁移之后,为了让服务B的上游服务能够访问到服务B,就不得不将服务B暴露出来。
同样,为了让服务B能够访问它的下游服务,就不得不将服务C暴露出来
原体系中只有服务A对外暴露,现在服务B和服务C也不得不暴露。而对外暴露服务,就意味着必然还会有一堆相关的工作需要完成:
- 认证
- 授权
- 加密
- ……
而这些都意味着:工作量/复杂度/更多的开发测试上线。
后续影响
随着应用往Service Mesh体系的逐渐迁移,我们开始迁移服务C和服务A。
先看服务C迁移到来的变化:
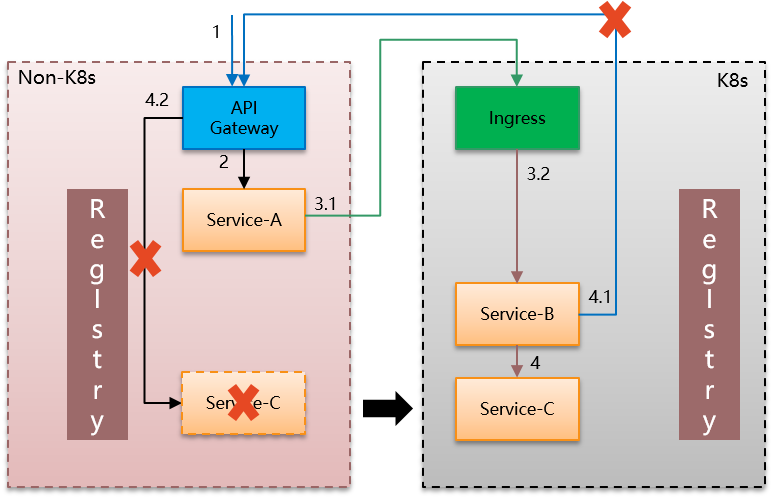
此时服务B到服务C的调用从原来的走API Gateway改变为Service Mesh体系内的服务间调用。然后API Gateway不再需要调用服务C,可以去除和服务C相关的内容。
再看服务A的迁移:
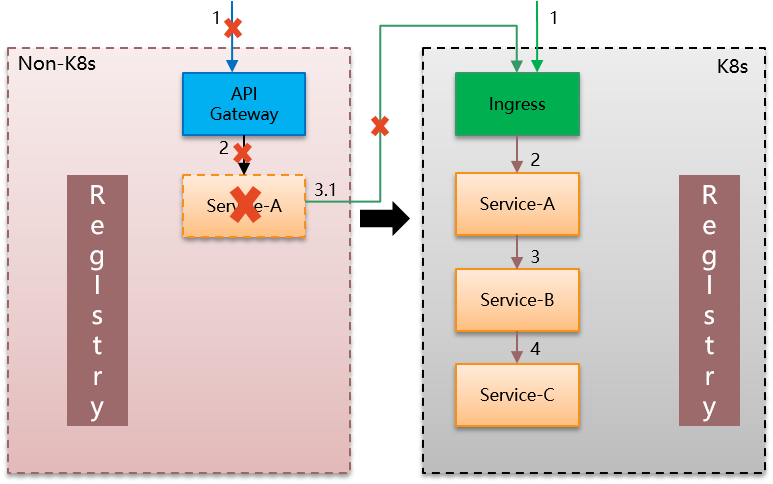
此时服务B不再需要暴露,而服务A的暴露方式发生变化,另外服务A调用服务B的方式也有改变。
我们抛开细节,只看整体:在服务A/B/C迁移到Service Mesh体系的过程中,服务间调用方式和对外暴露方式的变化,带来了一系列的工作量。而耗费这些工作量的中间环节,在整体迁移完成之后都会消失。换言之,都是迫不得已的临时投入,对最后的系统不产生增益。
直白一点:在过渡阶段的这诸多折腾,只是完成了服务迁移,而不能带来任何收益。这一点,无疑是令人沮丧的。
问题本质
反思一下:为何服务只是体系间迁移一下,就需要增加这么多不带来实际收益的工作量和复杂度?到底我们上面这些折腾是在做什么?
很明显,在这个过程中,我们没有任何业务改动,三个服务的实现也没有发生任何变化。
那么,改变的东西是什么?
是服务间通讯:
迁移过程中,服务A/B/C之间的通讯在业务语意上虽然依然属于东西向的服务间通讯机制,但是在实现上,却不得不临时转为南北向的网关到服务的通讯机制。
这个转变是无奈的,两个体系之间存在以下问题导致无法继续走东西向服务间通讯机制:
- 没有共同的registry,因此无法相互感知
- 没有可以直接连通的网络通道,原有的服务间通讯被迫走公开的API Gateway和Ingress通道
- 两个体系的服务间通讯机制也可能不同,导致迁移之后不得不重新实现服务间通讯机制
- API Gateway和Ingress对于服务暴露的方式也不尽相同,各种特性如认证/加密/服务路由等方式也很可能完全不同。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 wshten@gmail.com
文章标题:ServiceMesh--Ready for Cloud Native
本文作者:KevinTen
发布时间:2019-09-04, 00:00:00
最后更新:2019-09-04, 11:27:50
原始链接:http://github.com/kevinten10/2019/09/04/Cloud/servicemesh/Cloud-SM-问题-CloudNative/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

